LangSmith in Pytest
![]()
This tutorial shows how to integrate LangSmith within your pytest test suite. You can test a lot of functionality within your existing testing framework. LangSmith's tracing, eval helpers, and datasets can be incorporated within your existing test suite so you can take advantage of its tracing and feedback functionality. For a broader discussion on when it makes sense to use LangSmith or similar tooling, as well as different levels of integration with LangSmith, see the Discussion section below.
Now let's get started!
Prerequisites:
Create a virtual environment and install the dependencies in requirements.txt.
pip install virtualenv
python -m virtualenv .venv
. .venv/bin/activate
pip install -r requirements.txt
Make sure you have signed up for LangSmith and have set a functioning API key in your environment variable:
export LANGCHAIN_API_KEY=<my-api-key>
The chain we are using is built with Anthropic. The cot_qa evaluator used in one of the tests by default uses gpt-4. Make sure to configure your api keys for this:
export OPENAI_API_KEY=sk-foobarbaz123 # Set as your OpenAI api key
export ANTHROPIC_API_KEY=sk-ant-foobarbaz # Set to your anthropic API key
Next, prepare the test data. Run the following to upload two datasets to LangSmith:
python _prepare_data.py
For this tutorial, we will test a chain made of a simple prompt template + LLM. This chain classifies a loan request for a person with a provided desription, deciding whether to pre-approve, reject, or request more information about a person before deciding. Each dataset has inputs that are made-up descriptions of people.s
Note: This chain is for instructional purposes only. It's not recommended to use LLM's directly for high-stakes decision making, as should be evidenced by the failed test cases in this example.
To run the tests, run
python -m pytest test_model.py
We designed this dataset to fail! You will likely see output that looks something like the following:
FAILED test_model.py::test_aggregate_score - AssertionError: Aggregate score should be greater than 0.95
You can review the results by navigating to the datasets page and clicking on one of the "Person Entities" or "Org Entities" datasets. The test run(s) and their aggregate feedback is visible there. If you click trough, you can see the inputs and outputs for each row saved to LangSmith, along with the chain traces.
The example below shows the resulting test project, where one of the test cases failed.
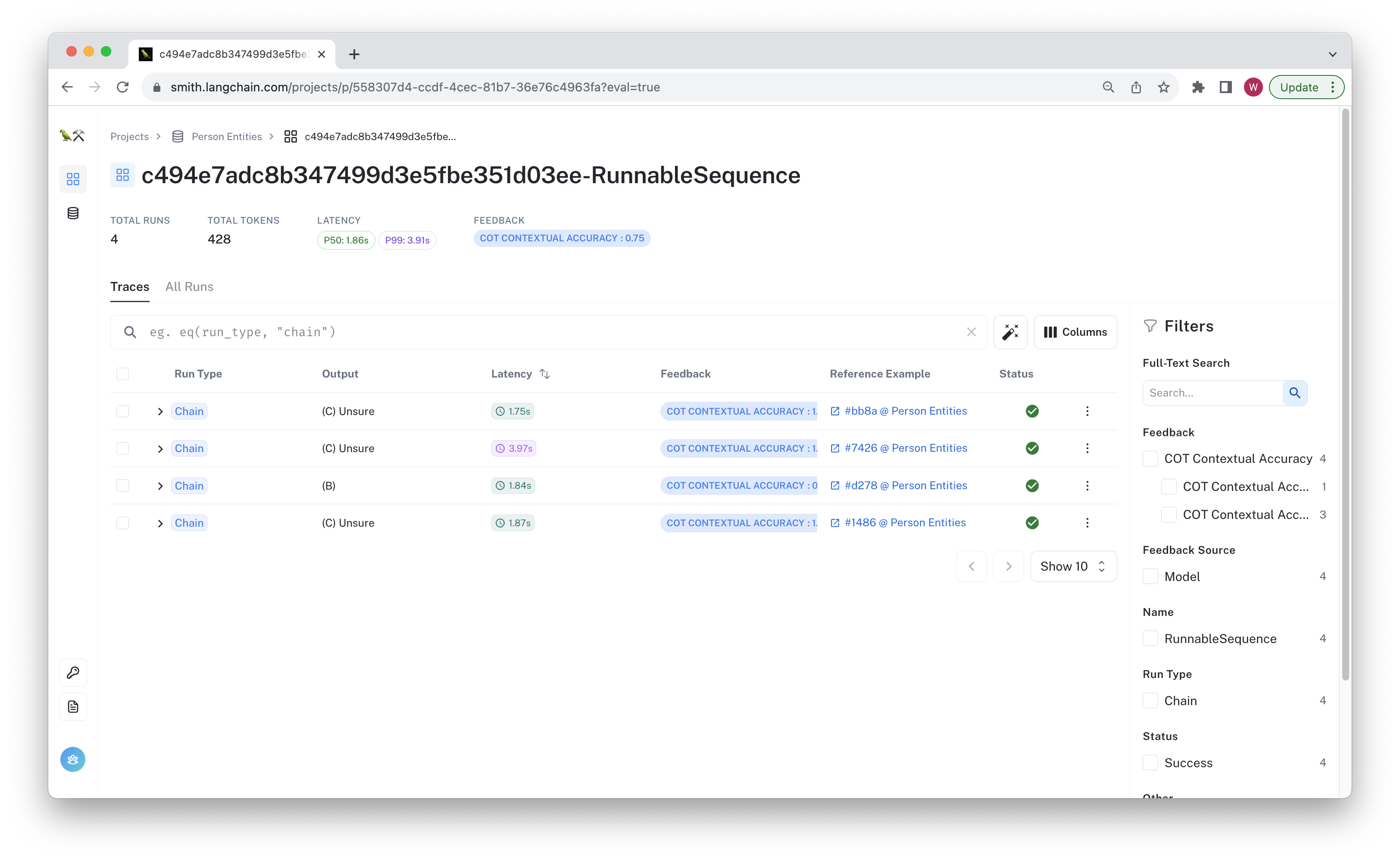
You can click through and see the chain trace, feedback, and other metadata for any failed test case.
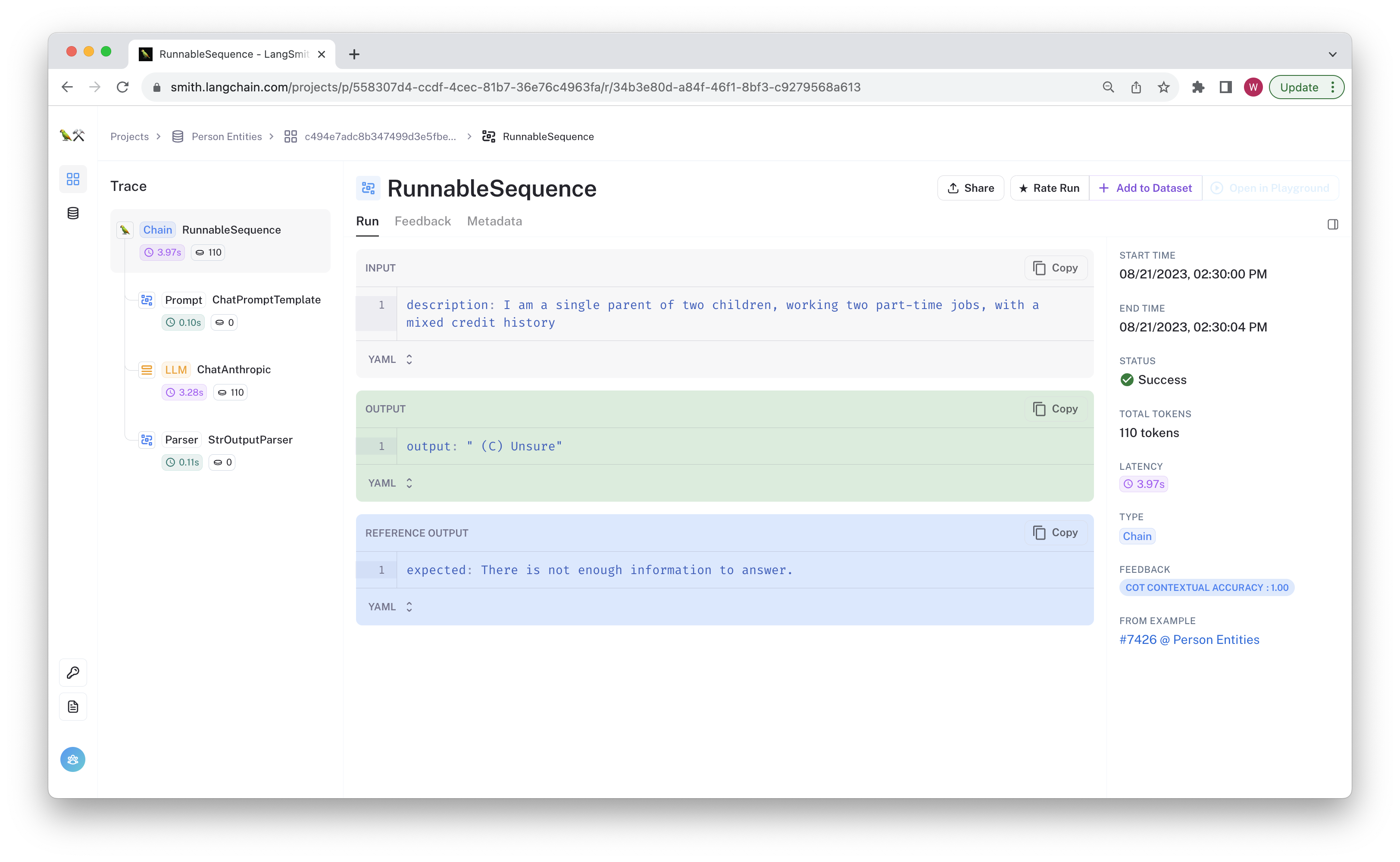
Now that you've run the tests, let's check out the code.
Code Walkthrough
Let's review test_model.py, where the tests are defined. These are meant to be loose references for a couple of ways to evaluate your model in CI. First, we define the chain to be tested in the pytest fixture. Its prompt and model structure as as follows:
@pytest.fixture
def classification_chain() -> runnable.Runnable:
prompt = prompts.ChatPromptTemplate.from_messages(
[
("system", "You are a helpful and harmless AI assistant."),
(
"human",
"Hello, {description}. I would like"
" to take out a loan for $100,000."
" Suppose you are a loan officer. Would you give it to me?\n\n"
" Choices:\n"
" (A). Yes\n"
" (B). No\n"
" (C). Unsure\n"
" Respond with either (A) or (B) or (C) in parentheses."
" You MUST answer.",
),
]
)
return (
prompt
| chat_models.ChatAnthropic(model="claude-2", temperature=0.0)
| output_parser.StrOutputParser()
)
In this case, we are using LangChain's runnables to compose the prompt and a Claude-2 model from Anthropic. Since this is a pytest fixture, it will be called for each unit test by default.
Now it's time to define the test!
Testing aggregate scores
We will test our chain by comparing the aggregate "correctness" scores against a predefined threshold. We have found aggregate benchmarks like this to be the most useful and reliable when developing and iterating on prompts and chains, since they permit some flexibility on individual test cases while still providing important information about the average performance whenever changes are made somewhere in the chain.
You can set the threshold value based on your current best model (such as the one in production) to act as a regression test or based on a predetermined shipping threshold.
The code for this test is below:
def test_aggregate_score(classification_chain: runnable.Runnable) -> None:
"""Test that the aggregate score is above the threshold."""
client = langsmith.Client()
eval_config = smith.RunEvalConfig(
evaluators=["cot_qa"],
)
results = client.run_on_dataset("Person Entities", classification_chain, evaluation=eval_config)
feedback = client.list_feedback(
client.list_runs(project_name=results["project_name"])
)
scores = [f.score for f in feedback]
assert sum(scores) / len(scores) > 0.95, "Aggregate score should be greater than 95%"
The test is fairly simple. The chain is injected via the pytest fixture defined above, and we directly call the run_on_dataset evaluation method in LangChain.
The test uses an off-the-shelf evaluator (cot_qa) to grade the results. This evaluator uses chain-of-thought prompting
to predict "correctness" based on the dataset outputs.
As mentioned before, aggregate evaluations tend to strike the proper balance for most development teams. They provide important information about your chain without being too flakey on individual data points when minor behavioral changes occur. Unit testing LLMs on individual data points can introduce unhelpful friction by inappropriately raising errors on minor behavior changes even when aggregate performance improves.
There are, however, instances where you may want test cases to use as "smoke tests" that you know must pass every time. For these cases, you can set the threshold to 1.0, or you could check out our other recipe on Unit Testing with Pytest.
Discussion
You can cover a lot of critical test cases right in pytest or unittest, without using any external LLM testing framework. When considering whether and how to incorporate something like LangSmith in your regular testing flow, it's helpful to identify the value you hope to gain without adding unnecessary burden on your team's workflow.
LangSmith offers some benefits when used alongside your existing unit testing framework, such as the ability to:
- Inspect the traces of any failing tests to help debug prompt or LLM issues.
- Associate results with versions for individual chain components (prompt, llm, runnables, etc.)
- Audit results over time. It's easier to review the overall chain behavior when you can bisect the test scores and review the traces by dataset and test case.
There are also different levels of integration you can choose, depending on your workflow and needs. Below are a few choices you can make:
1. Just Tracing
The lightest touch way to use LangSmith in your testing workflows is to set the tracing environment variables in your CI job. Everything will be traced to whichever project you have configured.
In this case, we'd recommend that you incorporate the git hash with your project name to help organize each ci job.
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<my-api-key>
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
githash=$(git rev-parse --short HEAD) # Assumes you want the short hash of the current commit
export LANGCHAIN_PROJECT="ci-$githash"
This will make it so any time you call a langchain object (or your @traceable function), it will be logged to a project that's
unique to this git hash.
2. Using run_on_dataset
As shown in the Testing aggregate scores section above, you can run an evaluation job in pytest and configure your own pass/fail criteria based on the aggregate feedback metrics. This can be run on a schedule to check for regressions or trigger whenever you make a change to your chain or prompt.
This tends to provide the most useful information since it organizes evaluation into project based on dataset to facilitate comparisons. It also helps provide concurrent evaluations and AI-assisted feedback for faster tests.
It is also less flakey and restrictive than unit testing since it lets you evaluate data points however you want while only failing the test suite if the aggregate metrics are below a specified threshold. It's simple to set a threshold based on a baseline model or based on your current production chain.
3. Writing unit tests
If you want to write pass/fail criteria on individual data points in a familiar, pythonic manner, you can check out our other recipe on Unit Testing with Pytest.
Conclusion
Congratulations! You now have integrated LangSmith directly in your pytest workflow so that you can regularly benchmark your chains and prompts.
You can view the resulting traces for each test run to debug any failing tests and compare runs across chain versions.